Initialize the Scene
A pre-trained single-image reconstruction model produces noisy Gaussian parameters that serve as the optimization target.
ICCV 2025
University of California, Riverside

Reconstructing 3D scenes from a single image is a fundamentally ill-posed task due to the severely under-constrained nature of the problem. Consequently, when the scene is rendered from novel camera views, particularly in unseen regions far away from the input camera, existing single image to 3D reconstruction methods render incoherent and blurry views. In this work, we address these inherent limitations in existing single image-to-3D scene feedforward networks. To alleviate the poor performance due to insufficient information beyond the input image's view, we leverage a strong generative prior in the form of a pre-trained latent video diffusion model, for iterative refinement of a coarse scene represented by optimizable Gaussian parameters. To ensure that the style and texture of the generated images align with that of the input image, we incorporate on-the-fly Fourier-style transfer between the generated images and the input image. Additionally, we design a semantic uncertainty quantification module which calculates the per-pixel entropy and yields uncertainty maps which are used to guide the refinement process from the most confident pixels while discarding the remaining highly uncertain ones. We conduct extensive experiments on real-world scene datasets, including in-domain RealEstate-10K and out-of-domain KITTI-v2, showing that our approach can provide more realistic and high-fidelity novel view synthesis results compared to existing state-of-the-art methods.
Single-image 3D reconstruction models are fast and convenient, but the input image simply cannot reveal what lies behind occlusions or beyond the observed camera frustum. As the camera moves away from the input view, deterministic reconstructions tend to average uncertain content, causing blurred geometry, missing structures, and inconsistent textures.
UAR-Scenes asks whether a generative prior can supply plausible missing information without corrupting the parts of the scene that were already observed. The answer is a post-hoc refinement loop: keep the reliable structure from the base reconstruction and learn from diffusion-generated views only where the generated supervision is semantically confident.
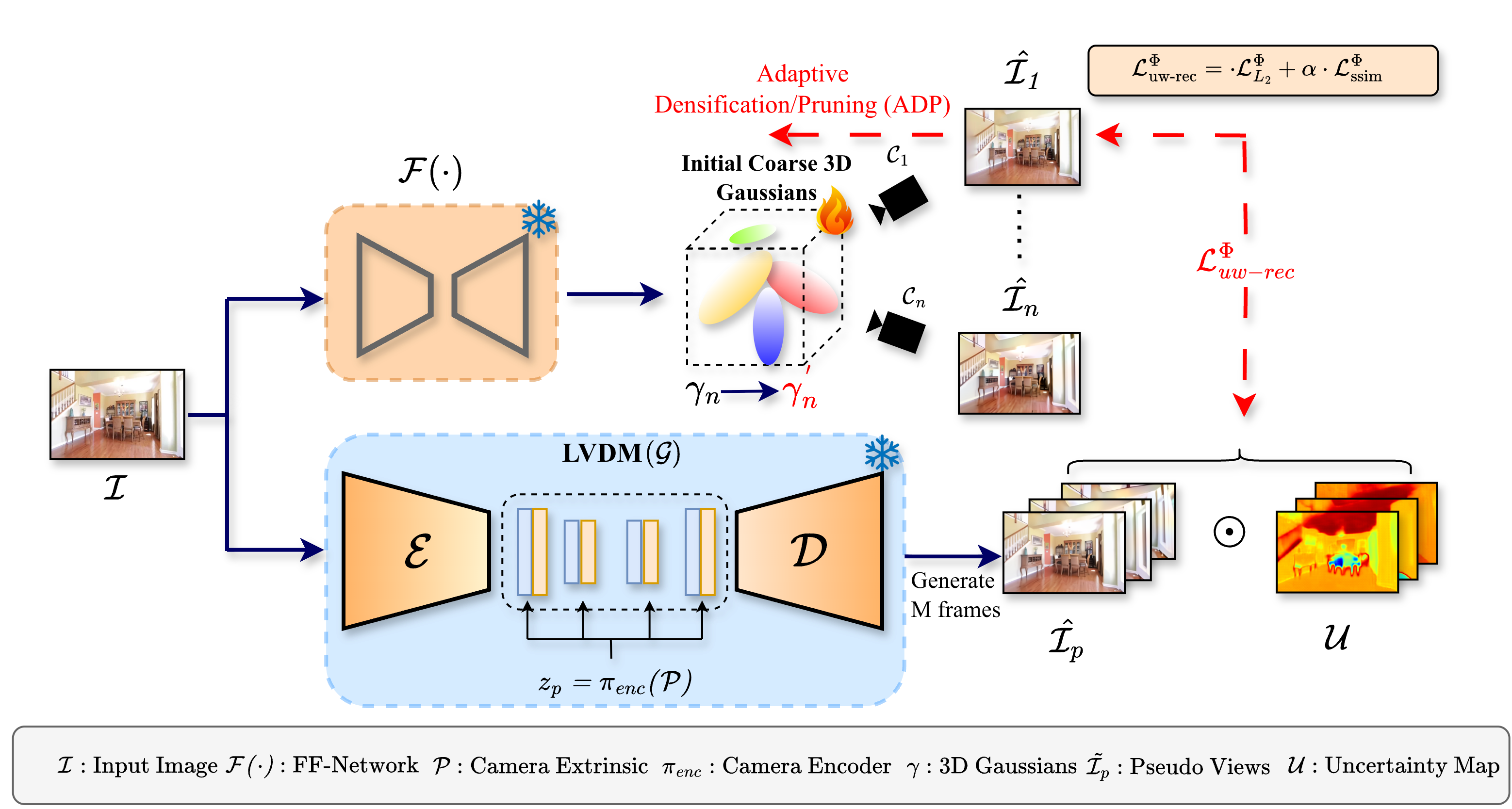
A pre-trained single-image reconstruction model produces noisy Gaussian parameters that serve as the optimization target.
A camera-controlled latent video diffusion model samples novel views for target poses, providing 2D supervision where no ground truth is available.
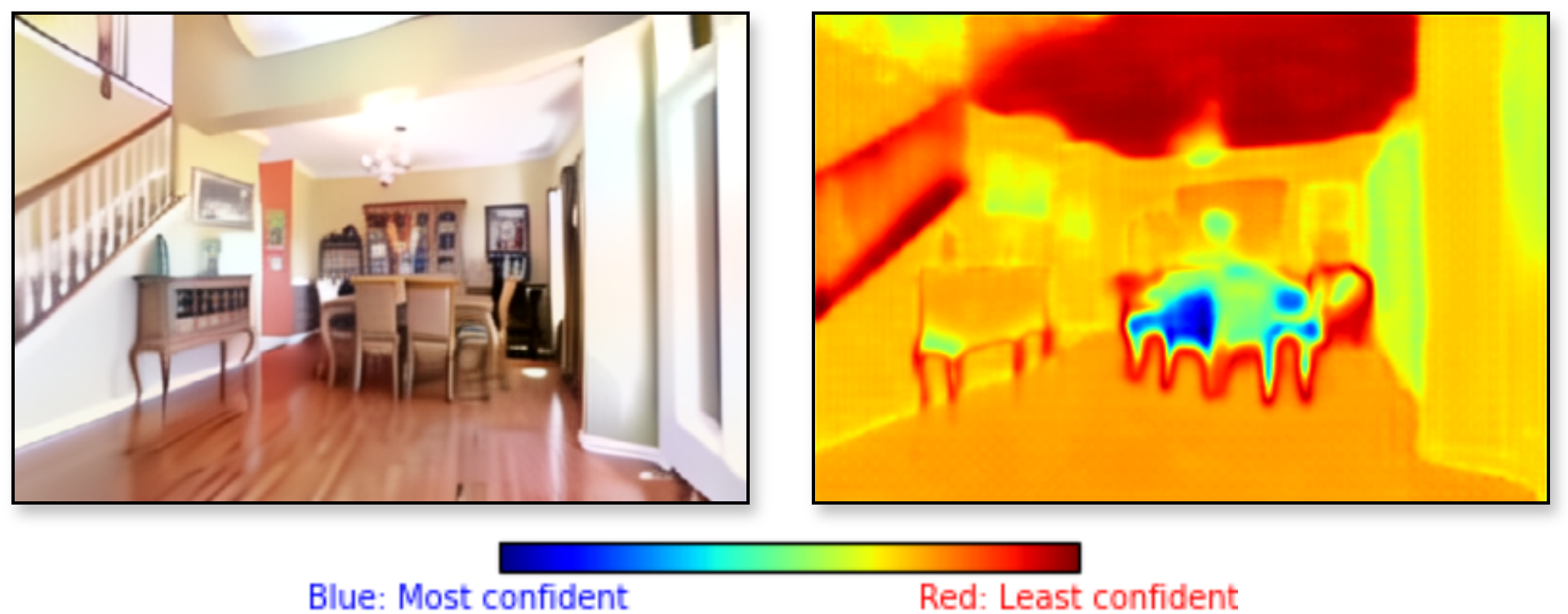
MLLM-assisted object tags and open-vocabulary segmentation produce per-pixel entropy maps that identify uncertain generated regions.
Uncertainty-weighted losses and Fourier style transfer guide optimization toward confident, texture-consistent completions.



| Method | 5f PSNR | 5f SSIM | 5f LPIPS | 10f PSNR | 10f SSIM | 10f LPIPS | Wide PSNR | Wide SSIM | Wide LPIPS |
|---|---|---|---|---|---|---|---|---|---|
| MINE | 28.45 | 0.897 | 0.111 | 25.89 | 0.850 | 0.150 | 24.75 | 0.820 | 0.179 |
| Flash3D | 28.46 | 0.899 | 0.100 | 25.94 | 0.857 | 0.133 | 24.93 | 0.833 | 0.160 |
| UAR-Scenes | 28.67 | 0.902 | 0.095 | 26.54 | 0.861 | 0.112 | 27.81 | 0.887 | 0.107 |
| Method | Int. PSNR | Int. SSIM | Int. LPIPS | Ext. PSNR | Ext. SSIM | Ext. LPIPS | Ext. FID |
|---|---|---|---|---|---|---|---|
| PixelNeRF | 24.00 | 0.589 | 0.550 | 20.05 | 0.575 | 0.567 | 160.77 |
| Du et al. | 24.78 | 0.820 | 0.410 | 21.23 | 0.760 | 0.480 | 14.34 |
| pixelSplat | 25.49 | 0.794 | 0.291 | 22.62 | 0.777 | 0.216 | 5.78 |
| latentSplat | 25.53 | 0.853 | 0.280 | 23.45 | 0.801 | 0.190 | 2.97 |
| MVSplat | 26.39 | 0.869 | 0.128 | 24.04 | 0.812 | 0.185 | 3.87 |
| Flash3D | 23.87 | 0.811 | 0.185 | 24.10 | 0.815 | 0.185 | 4.02 |
| UAR-Scenes | 26.37 | 0.871 | 0.125 | 24.37 | 0.819 | 0.144 | 2.55 |
| Method | PSNR | SSIM | LPIPS |
|---|---|---|---|
| LDI | 16.50 | 0.572 | - |
| SV-MPI | 19.50 | 0.733 | - |
| BTS | 20.10 | 0.761 | 0.144 |
| MINE | 21.90 | 0.828 | 0.112 |
| Flash3D | 21.96 | 0.826 | 0.132 |
| UAR-Scenes | 22.31 | 0.844 | 0.128 |

| Model | LVDM | FST | Uncertainty | PSNR | SSIM | LPIPS |
|---|---|---|---|---|---|---|
| Baseline | 24.93 | 0.833 | 0.160 | |||
| Baseline + LVDM | 27.24 | 0.867 | 0.126 | |||
| Baseline + LVDM-FST | 27.33 | 0.869 | 0.119 | |||
| UAR-Scenes | 27.81 | 0.887 | 0.107 |
@inproceedings{bose2025uncertainty,
title={Uncertainty-Aware Diffusion-Guided Refinement of 3D Scenes},
author={Bose, Sarosij and Dutta, Arindam and Nag, Sayak and Zhang, Junge and Li, Jiachen and Karydis, Konstantinos and Roy-Chowdhury, Amit K.},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2025}
}